Deep Mining: Auto-tuning machine learning pipelines
30 Jul 2015
I was a visiting student at MIT and worked on a project that we called Deep Mining. The goal was to automatically tune Machine Learning pipelines’ hyper-parameters through a repeated process of candidate sampling and evaluation. While working on this project, I mainly focused on Bayesian optimization methods and on Gaussian Process-based regression. In particular I developed a new regression algorithm, a non-parametric Gaussian Copula Process, that we used to better model the performance of a pipeline given its hyper-parameters. In addition, since the earlier stages of the pipeline can be computationally expensive (data processing, feature engineering..), I also worked on finding efficient methods to estimate pipeline performance via sub sampling.
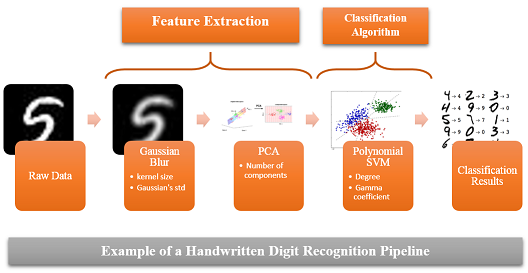
This project is still in active development and continues to grow, so check the project’s website for updates, and our code will soon be publicly available on GitHub. I am also part of an initiative to improve hyper-parameter optimization solutions within Scikit-Learn (see the PR here and here). Please contact me if you’d like to contribute.
Publications:
- Deep Mining: Copula-based Hyper-Parameter Optimization for Machine Learning Pipelines (Research thesis)
- Sample, Estimate, Tune: Scaling Bayesian Auto-Tuning of Data Science Pipelines (IEEE International Conference on Data Science and Advance Analytics, 2017)